在低配置设备上部署类似 FastGPT 的 AI 项目时,尤其在首次初始化阶段,常会出现系统响应缓慢、SSH 连接失败,甚至网络“堵死”的现象。这些问题的本质是 CPU、内存、磁盘 I/O 与网络资源同时达到上限,导致 Linux 系统调度阻塞。本文结合实际案例和经验,对资源瓶颈进行详细分析,并给出多种优化策略。
一、初始化阶段的资源压力分析
FastGPT 初始化主要包括以下几个阶段,每个阶段都会对系统资源产生不同压力:
1. 镜像或模型拉取
-
操作:通过 Docker 或 pip 下载模型权重、镜像、依赖包。
-
资源消耗:
- 网络:大量并发请求占满带宽,尤其是低带宽网络容易出现拥塞。
- 磁盘:写入临时缓存或最终模型文件。
-
案例表现:
- 带宽 10-20 Mbps 的低配设备,镜像下载速度常被限制在 1-2 MB/s。
- 同时进行其他 I/O 操作时,磁盘延迟增加,系统卡顿明显。
2️. 服务启动
-
操作:启动多个 FastGPT 服务模块(API 服务、索引服务等)。
-
资源消耗:
- CPU:多线程初始化,尤其是加载模型或执行前处理逻辑。
- 内存:每个服务进程会占用一定 RAM,累积易触发 swap。
-
案例表现:
- CPU 占用率短时间达到 100%,系统调度延迟。
- SSH 登录时,输入命令延迟明显,甚至新连接超时。
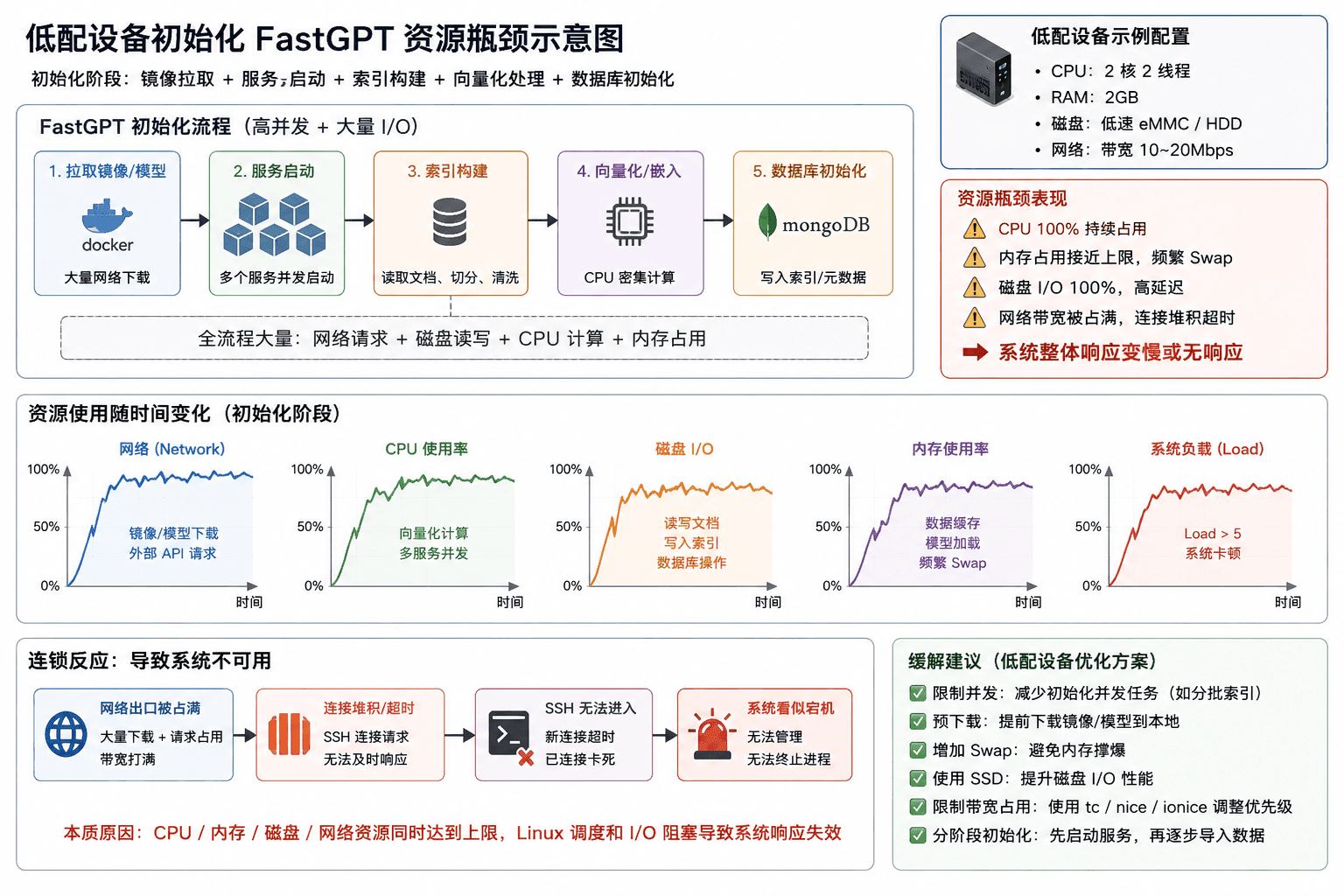
3️. 索引构建
-
操作:读取本地文档、切分、清洗,并生成向量索引。
-
资源消耗:
- 磁盘 I/O:大量随机读写。
- CPU:文本处理与向量化计算。
- 内存:缓存文档数据和索引。
-
案例表现:
- eMMC 或低速 HDD 设备,I/O 阻塞导致索引构建速度大幅下降。
- 高并发索引写入可能导致系统整体 load > 5,SSH 操作延迟。
4️. 向量化计算 / 嵌入生成
-
操作:模型生成向量表示。
-
资源消耗:
- CPU 或 GPU:密集计算。
- 内存:大模型权重加载与中间缓存。
-
案例表现:
- CPU 占用持续 100%,Swap 频繁。
- 系统整体响应变慢,网络请求可能堆积。
5️. 数据库初始化
-
操作:写入索引、元数据到数据库(如 MongoDB)。
-
资源消耗:
- 磁盘 I/O:大量小文件写入或数据库事务。
- 内存:数据库缓存。
- CPU:写入索引的处理逻辑。
-
案例表现:
- 写入延迟显著,网络出口可能出现拥塞。
- SSH 新连接经常超时或无响应。
二、低配设备的连锁反应案例
结合实际测试与经验,低配设备初始化 FastGPT 时可能出现如下连锁瓶颈:
-
网络出口占满
- 大量模型下载 + API 请求 → 带宽打满 → 新的 SSH 连接请求无法及时响应。
-
连接堆积 / 超时
- CPU / I/O 占满 → 系统调度延迟 → SSH 连接队列堆积,部分连接超时。
-
SSH 无法进入
- 已建立的连接卡死,新连接无法进入 → 系统看似“假死”。
-
系统整体负载高
- load > 5-10,CPU 占满,Swap 频繁触发,磁盘 I/O 延迟严重 → 影响所有服务。
本质原因是 CPU / 内存 / 磁盘 / 网络资源同时接近上限,Linux 调度和 I/O 阻塞导致系统整体失效。
三、常规缓解方案
-
限制并发
- 减少线程数或批量处理索引,避免瞬时资源爆满。
-
预下载依赖
- 在本地或高性能设备下载 Docker 镜像、模型权重,降低初始化阶段网络压力。
-
增加 Swap 或内存
- 避免内存溢出和进程被杀。
-
使用 SSD
- 提升磁盘随机读写性能。
-
网络优化
- 调整 TCP 参数或使用
tc/nice/ionice对进程和流量进行优先级控制。
- 调整 TCP 参数或使用
四、额外优化方案
-
本地物理机 WSL 完整初始化
- 利用本地硬件完成完整索引、模型加载和 Docker 打包。
- 上传镜像到远程服务器,避免远程初始化阶段的大量并发压力。
-
云厂商竞价实例
- 使用 AWS Spot 或 Azure Low-Priority VM 完成初始化。
- 高性能实例短时间内完成索引构建,降低本地设备压力。
-
升级硬件
- 更高性能 CPU、更多 RAM、SSD 存储。
- 提升初始化速度,减少 swap 与 I/O 阻塞。
-
本地“家里云”部署 + FRP 映射
- 在家用设备部署,利用 FRP 映射到公网。
- 配合 CDN 做源站防护,适合低并发环境,节省云成本。
五、总结
-
瓶颈来源:CPU 占用率高、内存频繁 swap、磁盘 I/O 阻塞、网络出口拥塞。
-
表现形式:SSH 登录延迟、系统 load 高、服务响应慢、网络请求堆积。
-
缓解策略:
- 软件层面:限制并发、批量处理、优先级调度、预下载。
- 部署策略:本地高性能初始化、云竞价实例、硬件升级、本地家用云。
< Back to blog list通过合理资源调度与部署策略,可以在低配环境下安全、稳定地运行 FastGPT,避免系统卡死和 SSH 无响应。